A fundamental challenge in autonomous driving is the integration of high-level, semantic reasoning for long-tail events with low-level, reactive control for robust driving. While large vision-language models (VLMs) trained on web-scale data offer powerful common-sense reasoning, they lack the grounded experience necessary for safe vehicle control in driving scenarios. We posit that an effective autonomous agent should leverage the world knowledge and common-sense reasoning of VLMs to guide a grounded, steerable driving policy toward safe and robust control. To this end, we propose SteerVLA, which uses reasoning from VLMs to produce fine-grained language instructions that steer a vision–language–action (VLA) driving policy. Key to our method is the language interface between the high-level VLM and low-level VLA, which allows the high-level policy to better ground the nuances of its reasoning in the control outputs of the low-level policy. To provide fine-grained language supervision aligned with vehicle control, we leverage a VLM to augment existing driving data with dense language annotations in hindsight, which we find to be essential for effective reasoning and steerability. We evaluate SteerVLA on a challenging closed-loop benchmark, where it outperforms state-of-the-art methods by 4.77 driving score overall and by 8.04 points on a long-tail subset.
SteerVLA
We focus on the challenge of long-tail driving scenarios, where rare and unanticipated events require strong generalization and common-sense reasoning from the policy. VLAs are a strong backbone for driving because they combine semantic grounding from vision–language pretraining with domain-specific adaptation obtained via imitation learning on driving data. Building on this capability, we leverage the reasoning and semantic inference abilities of VLMs and ground these inferences in driving control through fine-grained meta-actions that steer a VLA policy. Concretely, a high-level policy first reasons about the driving scene, historical vehicle states, and routing command to produce a meta-action, accompanied by a short reasoning trace that reasons over driving scenes and helps the policy generate more appropriate meta-actions. The low-level VLA then predicts future waypoints conditioned on both the observation and the meta-action. This design improves generalization by offloading high-level reasoning to the high-level policy, while allowing the VLA to specialize in fast and accurate waypoint prediction conditioned on the high-level’s instructions.
Experiments
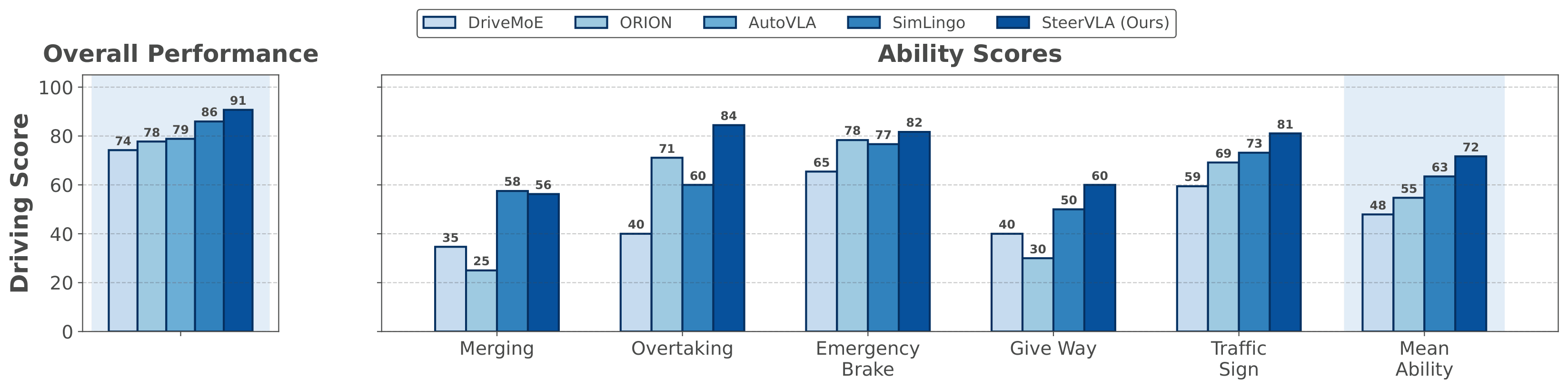
On Bench2Drive, we report overall performance and per-ability scores for SteerVLA across five advanced urban driving skills. SteerVLA significantly outperforms prior approaches, benefiting from improved reasoning and instruction-following capabilities.

We compare SteerVLA with the state-of-the-art method SimLingo on Bench2Drive-LongTail. SteerVLA exhibits larger performance gains in long-tail scenarios, likely because these cases require more complex reasoning and more precise control.
Scenario Rollouts
Below are sample closed-loop rollouts from SteerVLA in a variety of driving scenarios.
The vehicle must merge around an accident blocking the road.
A car in the oncoming lane turns into the current lane.
The vehicle is turning and must yield to a pedestrian crossing the road.
The vehicle encounters a jaywalking pedestrian crossing the road.
The vehicle ahead brakes suddenly.
A static vehicle cuts in front of the ego vehicle on the highway.